准备工作
- 7.4.0版本适用的 ik-analyzer 分词器jar包
- mysql-connector-java-5.1.40.jar mysq数据库链接驱动jar包
- data-config.xml 数据库的链接配置文件
本地环境
- MacOS
- Docker CE
安装单机版Solr服务
1、拉取solr 7.4.0镜像
docker pull solr:7.4.02、启动 solr 容器,尝试访问 http://ip:8983/
docker run --name solr -d -p 8983:8983 -t solr:7.4.03、创建一个 SolrCore,名称为 myIKCore
docker exec -it --user=solr solr bin/solr create_core -c myIKCore
4、配置中文分词 ik-analyzer
// 复制对应的分词jar包到容器内
docker cp /www/docker/solr/ik-analyzer-8.3.0.jar solr:/opt/solr/server/solr-webapp/webapp/WEB-INF/lib
docker cp /www/docker/solr/ik-analyzer-solr7-7.x.jar solr:/opt/solr/server/solr-webapp/webapp/WEB-INF/lib
docker cp /www/docker/solr/solr-dataimporthandler-8.4.0.jar solr:/opt/solr/server/solr-webapp/webapp/WEB-INF/lib
docker cp /www/docker/solr/solr-dataimporthandler-extras-8.4.0.jar solr:/opt/solr/server/solr-webapp/webapp/WEB-INF/lib5、复制mysql数据连接驱动到容器内
docker cp /www/docker/solr/mysql-connector-java-5.1.40.jar solr:/opt/solr/server/solr-webapp/webapp/WEB-INF/lib6、配置数据库配置文件到刚刚创建的 myIKCore/conf 目录内
docker cp /www/docker/solr/data-config.xml solr:/opt/solr/server/solr/myIKCore/conf// data-config.xml
<?xml version="1.0" encoding="UTF-8"?>
<dataConfig>
<dataSource name="source1" type="JdbcDataSource"
driver="com.mysql.jdbc.Driver"
url="jdbc:mysql://192.168.1.10:3306/hjsystem"
user="root"
password="1234567890"
batchSize="-1" />
<document>
<entity name="myData" dataSource="source1"
query="SELECT id, applySn, enterpriseName, productName, FROM table">
<field column="id" name="id" />
<field column="applySn" name="applySn" />
<field column="enterpriseName" name="enterpriseName" />
<field column="productName" name="productName" />
</entity>
</document>
</dataConfig>
// 参照你自己的数据库连接地址,以及你自己的表信息来配置,需要在solr中查询哪些字段,就配置哪些字段7、配置IK分词器
// 进入容器
docker exec -it --user=root /bin/bash// 更新软件库,安装 vim
apt-get update
apt-get install vim// 定位到 myIKCore/conf 目录内
cd /opt/solr/server/solr/myIKCore/conf
// 编辑文件夹内 managed-schema 文件
vim managed-schemashift + g 定位到文件末尾,插入如下配置
<!-- ik分词器 -->
<fieldType name="text_ik" class="solr.TextField">
<analyzer type="index">
<tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" useSmart="false" />
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" useSmart="true" />
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType>
<field name='applySn' type="text_ik" indexed="true" stored="true"/>
<field name='enterpriseName' type="text_ik" indexed="true" stored="true"/>
<field name='productName' type="text_ik" indexed="true" stored="true"/>配置好后,大致如图:

applySn,enterpriseName,productName 是我数据库的字段,与第6步骤中,data-config.xml对应。id 因为 managed-schema 已经有了,所以就不用填写了不然会冲突错误。
8、配置 solrconfig.xml 配置导入把当初配置好的 data-config.xml 导入到 solr 中
// 定位到如下目录
cd /opt/solr/server/solr/myIKCore/conf/
// 编辑
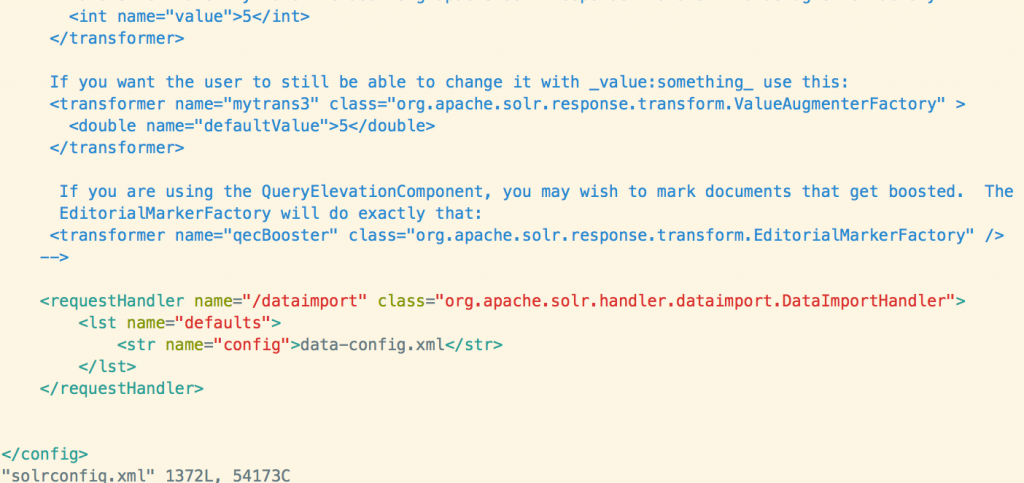
vim solrconfig.xmlshift + g 定位到文档末尾,插入如下内容:
<requestHandler name="/dataimport" class="org.apache.solr.handler.dataimport.DataImportHandler">
<lst name="defaults">
<str name="config">data-config.xml</str>
</lst>
</requestHandler>配置好后,大致如图:
9、至此,我们所有的配置工作已基本完成,接下来重启容器
docker restart solr然后打开 http://192.168.1.10:8983/solr/#/myIKCore/analysis 测试一下我们的中文分词是否正常工作。注意地址替换成你自己的ip
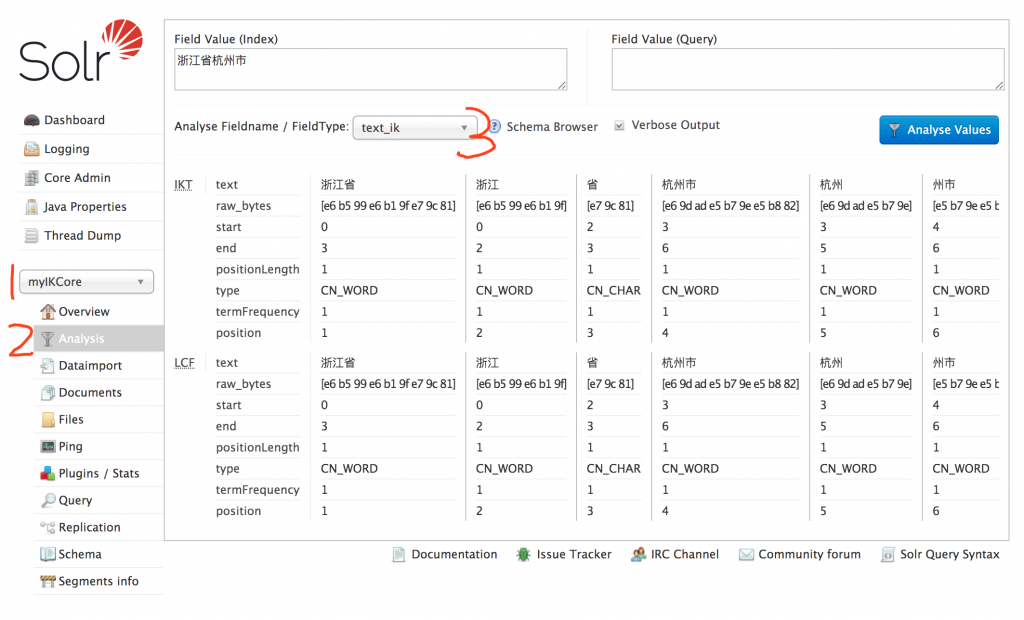
我们选择创建的 myIKCore , 选择 Analysis 分析,FieldType 中选择 我们配置的中文分词 text_ik , 然后在 Field Value 中输入一段中文,点击 Analyse Values 可以看到已经实现了中文分词效果。
10、接下来把我们mysql中的数据导入到 solr 中
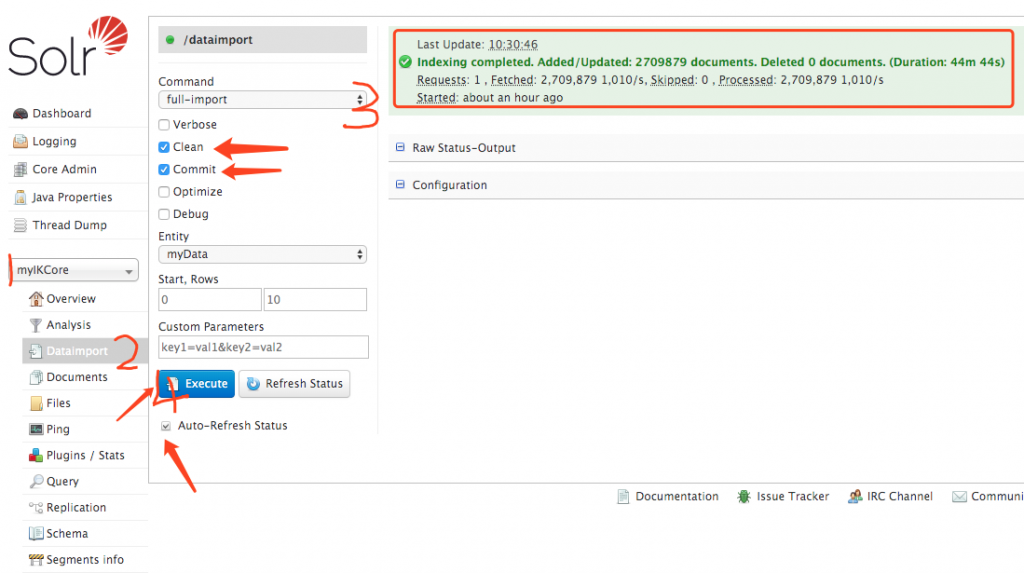
我们选择创建的 myIKCore ,选择 Dataimport
选择full-import 勾选 Clean、Commit
Entity 选择我们 data-config.xml 配置的 Entity myData
勾选Auto-Refresh Status
点击 Execute 执行。这个时候,solr 会创建一个线程来导入mysql的数据
当导入完成后,右上角会绿色提示,导入工作的所有信息,比如我这个表有270万数据,用时44分44秒
11、导入完成后,我们来测试一下查询效果
我们选择创建的 myIKCore ,选择 Query
q输入框中输入 *关键词*
dl 是输出的字段,可不填写
df 查询字段 例如输入 productName (你导入后data-config.xml中定义的查询字段)
然后点击 Execute Query 查询
我们可以看到在右侧,已经为我们模糊匹配了查询结果
雷雷
这个人太懒什么东西都没留下
文章评论(0)